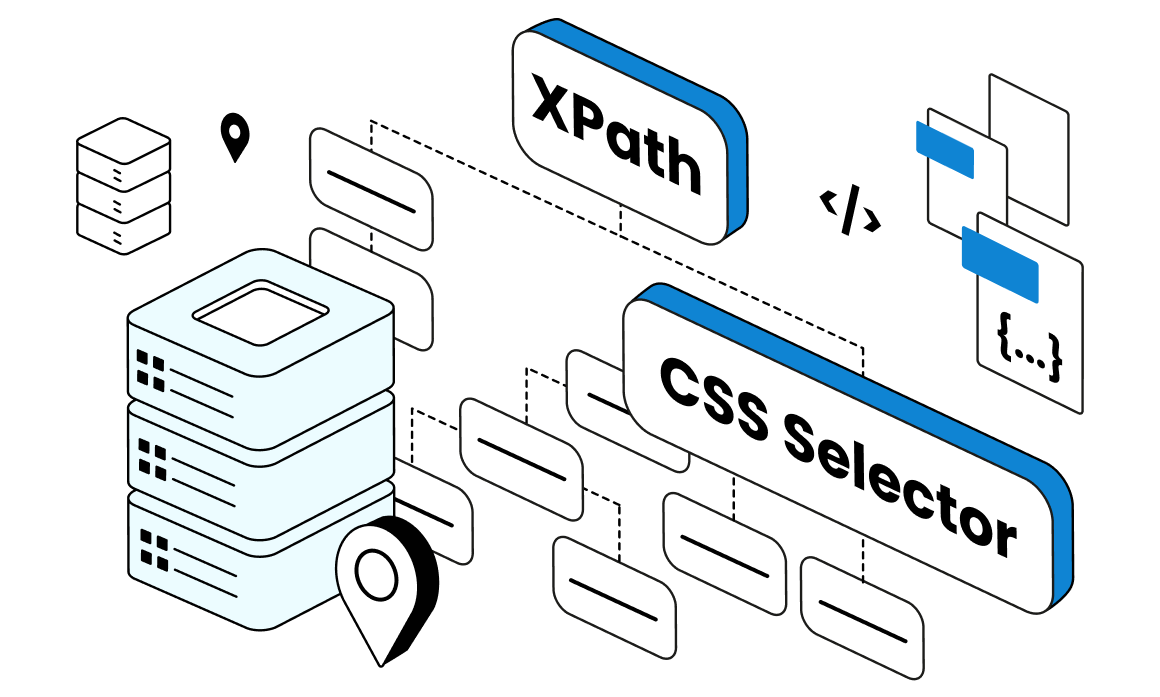

We can’t get anywhere in data scraping without a good locator. These smart automated tools dive deep into a DOM tree and pick out the elements we need for our databanks. Two programs often come up in conversation when choosing the best locator for the job. Some swear by an XPath locator while others recommend a CSS locator. Is one any better than the other? Let’s take a look at CSS Selector vs XPath to see which is the ideal choice for your project.
What is XPath?
Let’s start with XPath. This tool is the perfect accomplice for your new scraping proxy. As you crawl the web for competitors’ sites and begin extracting valuable data, XPath can come in to deal with any interesting XML documents you come across. It can literally scrape pages from top to bottom, giving you the best chance to reveal its deepest secrets. Just make sure to use the right relative or dynamic path with specific axes.
Advantages of XPath
What makes XPath such a popular choice when picking the best data extraction tool? Well, it all comes down to its diversity and high functionality. You can do a lot here, and pick the path that’s right for you. For example, maybe you want to focus on a document’s root rather than a specific element. Maybe you want to take a few different approaches to get every last piece of data possible.
XPath lets you do all this via a more complex and adaptive system. You can use bidirectional traversal of DOM trees and a range of advanced options to target all kinds of elements. Users find they can utilize XPath on most browsers with great results.
What is CSS Selector?
Next up in this comparison of Xpath vs CSS Selector, we have CSS Selector. At its root, the basic function of CSS Selector is the same. You’re building a unique syntax with all the right elements to locate key webpage data. The difference here is that you can follow strings of HTML elements through either an element or an ID selector. Just think of it as using a slightly different language to communicate with different elements.
Advantages of CSS Selector over XPath.
There are lots of reasons to love XPath, and many users do find it meets their needs while using your residential proxy. However, the complexity of this program does put a lot of new users off, and understandably so. There are so many options and adaptations that it gets a little overwhelming. You may also find your computer’s performance decreases while XPath gets to work. This isn’t quietly working in the background unnoticed, so be careful when you schedule your queries.
CSS Selector isn’t as complicated as XPath, which means you should be able to learn its features and syntax a little faster. The user-friendly nature of CSS Selector makes it a winner for anyone new to data scraping. Many say this tool is much more intuitive and they quickly get the hang of developing an effective syntax with the right operators. Furthermore, you get great cross-browser compatibility here for greater access to different platforms.
The downside to this more straightforward approach is that you don’t have the same bidirectional system. You can only go parent-to-child, not the other way. You may also find that the system doesn’t provide the same choice in its selectors. XPath is the more powerful choice to help you traverse web elements more effectively.
Which to Use: XPath or CSS Selector?
Ultimately, your choice here comes down to your experience level. If you have a lot of confidence in data scraping and know precisely what you want, go with XPath. That extra attention to detail with the options and routes gives it an edge over CSS Selector in terms of performance. It can find more XML data in a way that suits your specific queries. Users who get to grips with the tools and overcome any performance issues tend to find this is a more customizable and interesting tool.
CSS Selector, meanwhile, is a much better choice for anyone concerned about the learning curve. XPath is smart and in-depth, but not beginner-friendly. CSS Selector offers that more supportive stepping stone into the world of data scraping. It has its limitations, but this is only a problem for more experienced users.
XPath vs CSS Selectors: Conclusion There is no right or wrong choice here. Each of these clever locator tools has the potential to extract a lot of helpful information. You just need to choose the right one to access the best selectors and target the right web elements. You could start out with the faster, more beginner-focused CSS Selector for HTML. Get the hang of these functions, gain confidence, and then see how you get on with XPath. You can always use both with a top static residential proxy for the ultimate data scraping experience.
Frequently Asked Questions
Please read our Documentation if you have questions that are not listed below.
-
Should you use a proxy when working with XPath or CSS Selector?
Yes. It is always a good idea to go anonymous with a top datacenter proxy when working with any scraping tools. Set yourself up with a strong datacenter rotating proxy for greater peace of mind. It will provide a barrier between your IP and the target website, bypassing any blockers and bans.
-
Are there compatibility issues with XPath?
Yes. You may have read that some browsers don't accept the more recent XPath updates, and that's true. This could limit its functionality and you may have to revert to older versions. Luckily, that isn't the case with CSS Selector.
-
Which is faster? CSS Selector or XPath?
This is another reason to choose CSS over XPath, especially if you are a new user. The performance issues mentioned above do mean that XPath is a little slower to extract data. CSS Selector will get in and out much faster so you can get on with your project. Still, some would argue it is worth the wait to get that extra information from XPath.
Top 5 posts


4chan is a highly popular image board famous for its loose censorship rules. But even with these freedoms, your activity on the platform can be banned or restricted. In this article, we will look at how to use 4chan with a proxy to bypass any blocks.